Akka cluster介绍
#akka cluster介绍
Akka Cluster提供了一个可容错、去中心化的,基于点对点的集群成员服务(membership service),解决了单点故障和单点瓶颈问题。
##名词
### node
cluster的逻辑成员。 在一个物理机器上可能存在多个node。以 hostname:port:uid 的元组定义。在本文种,任何地方提到节点其含义等同于node。
###cluster
一组由membership service组合在一起的节点。在本文中任何提到集群起含义等同于cluster。
###leader
集群中的一个节点,作为该集群的leader。管理集群同步,分区,故障恢复,重负载均衡等(很多功能目前没有实现)。
##membership
一个集群有一组节点组成。每一个节点由一个hostname:port:uid元组标识。一个基于Akka的应用可以分布在一个集群上,集群中的每一个节点支撑起应用的一部分功能。
Akka应用中的集群membership和分区是解耦的。一个没有任何actor的节点也可以是一个集群的成员。加入一个集群是通过向集群中的任一节点发起一个Join命令来实现的。
在(集群?)内部节点标识包含一个UID来唯一的标识在该hostname:port上的这个actor system实例。
Akka使用UID来触发可靠的远程death watch。这意味着同一个actor system被移除后将无法再次加入一个集群。
要让一个actor system再次加入一个集群,需要停止这个actor system并再次启动来获取一个新的UID。
集群的membership状态是一个特化的CRDT,这意味着它拥有一个monotonic合并函数。当并发改变发生在不同的节点上时,更新将会被合并,最终结果将会一致。
###gossip
Akka中使用的集群membership基于Amazon的Dynamo系统,Basho’s’的Riak分布式数据库使用了同样的方法。 集群membership使用Gossip协议来进行通信,集群的当前状态会被随机的在集群内部’gossip’,集群中的成员有可能看到非最新的版本。
####VECTOR CLOCKS <!— Vector clocks are a type of data structure and algorithm for generating a partial ordering of events in a distributed system and detecting causality violations.
We use vector clocks to reconcile and merge differences in cluster state during gossiping. A vector clock is a set of (node, counter) pairs. Each update to the cluster state has an accompanying update to the vector clock. —>
Vector clocks是一种用来在集群中生成偏序的事件并检测因果性冲突的数据结构和算法。
在’gossip’的过程中,Akka集群使用vector clocks来合并集群状态并使其一致。一个vector clock是一个(node, counter)对。每一次对集群状态的更新都有一个对应的vector clock更新。
####GOSSIP CONVERGENCE
在某个时刻,集群的信息在一个节点本地是一致的。这仅发生在当一个节点可以确认它正在观察的集群状态也同时被集群中的所有其他节点观察。
Convergence是通过将gossip过程中看到当前版本的状态的节点到一个set来实现的。这个信息在gossip概述中被称作为seen set。当所有的节点都被包含在这个seen set中时就有了convergence。
当有任何节点无法被集群联系时,Gossip convergence就不会发生。节点需要重回可联系(reachable)状态,或者被设置为down并移除在状态(见Membership生命周期段落)。
这种情况仅会阻挡leader进行集群membership管理,并不会影响应用执行。
这意味着在网络分区时,无法向集群中添加节点。节点可以加入,但是直到分区被修复或无法联系的几点被置为down,它们都无法被置为up状态。
####FAILURE DETECTOR
failure detector负责尝试检测一个节点是否无法被集群中的其他节点联系(unreachable)。
Akka使用了一个The Phi Accrual Failure Detector的实现来。
一个精确的failure detector会将监控和解释解耦。这使得它能适用于更多的场景并能构建出更通用的失败检测服务。
构建的思想是它会保存失败统计历史,从其他节点的心跳计算,尝试通过多个指标去做合理的猜测,并且结合这些指标如何随时间推移而累加,来更好的猜测出一个节点状态是up还是down。
它会返回一个phi值来表述节点down的可能性,并非仅仅对“这个节点是否down了”回答是或否。
用户配置的threshold是这个计算的基础。低的threshold会产生很多错误的怀疑但是在一次真实的崩溃发生时可以保证快速发现。相反的,高的threshold生成的误报较少,但是需要更多的时间来发现一次真实的崩溃。
默认的threshold为8,这个值适用于大多数场景。但在云环境中,例如Amazon EC2,这个值可以被增加到12,来应对这类平台可能发生的网络问题。
在一个集群中每一个节点会被集群中其他的几个(默认最大值为5)节点监控,当其中任意一个节点检测到这个节点为unreachable时这个信息通过gossip将被传播到集群中的其他节点。换句话说,只需要一个节点将某个节点标记为unreachable,集群中的其他所有节点就会将该节点标记为unreachable。
被监控节点选自一个hashed有序节点环的邻居。这是为了增加跨机架和数据中心监控的可能性, 但是在所有节点上环的顺序是相同的,保证了集群可以完全收敛。
心跳每秒都会发出,每一个心跳都会执行一个request/reply握手,reply会作为failure detector的输入。
failure detector也会检测出节点恢复为reachable。当所有监控一个节点的节点都检测到被监控节点状态为reachable时,经过gossip传播,将会考虑将其置为reachable。
如果系统消息无法被递送到一个节点,它将会被隔离,并且无法从unreachable状态回归。
这种情形可能发生在有过多没有被ack的系统消息时(例如watch,Terminated,远程actor部署,远程parent管理actor故障)。
这个节点只有被置为down或removed状态(见membership生命周期)并且重启actor system后才可以再次加入集群。
####LEADER
在gossip收敛后集群可以决定一个leader。其间并不存在leader选举的过程,只要达到gossip收敛,leader总能被任意的节点确定认出。
leader仅仅是一个角色,任何节点都可以成为leader,leader在各轮收敛也可能改变。
leader是有序节点中可作为leader的第一个节点,leader的member状态可以是up和leaving。
leader负责将集群的成员移入或移出集群,将加入集群的成员状态改为up或将已存在的成员改为removed状态。
leader的动作仅在收到一个包含gossip收敛的新集群状态时被触发。
经过配置,leader可以根据Failure Detector来“auto-down”一个unreachable节点。
这意味着在一个配置的时间内,自动将unreachable节点设置为down。
####SEED NODES
种子节点是为新节点加入集群而配置的联系点。当一个新节点启动后它会向所有种子节点发消息,然后向第一个应答的种子节点发送join命令。
种子节点的配置值对运行中的集群本身没有任何影响,它仅与有新节点加入集群联系,因为它帮助新节点找到join命令的接受者。 一个新成员可以发送这个命令到任意现有集群节点,不必是种子节点。
####GOSSIP PROTOCOL
akka使用了一种push-pull的gossip变种来减少gossip信息的大小。 在push-pull gossip中使用一个摘要来代表当前版本而非使用实际的值。 如果接受者如果有更新的版本,可以发回任意值。如果接受者拥有过期版本,也可以请求实际值。 Akka使用包含一个vector lock的共享状态来控制版本, 所以Akka中的push-pull gossip变种仅在需要时使用这个版本来推送实际的状态。
以1秒为周期,每个节点随机的选择另一个节点进行一轮gossip。如果seen set中的节点少于一半那么集群每秒钟会进行3轮gossip。 这个调整机制可以加速状态改变后早期传播阶段的收敛过程。
gossip节点的选择是随机的但是倾向于选择有可能未看到当前版本状态的节点。 在每次gossip信息交换中且集群未能收敛时,节点使用0.8(可配置)的概率来和没在seen set的节点进行gossip。 否则就跟任意活着的节点进行gossip。
这种带有倾向性的选择是为了提高状态变化后期传播阶段的收敛速度。
对包含了多于400个节点的集群(可配置,400是经验值),0.8这个概率应该逐渐降低以避免过多的并发gossip把单个掉队者淹没。 gossip接受者同样有一种机制来保护自己,他会将mailbox中入队时间过长的消息丢弃。
当集群在一个收敛状态时参与gossip的节点仅会向选定的节点发送一个很小的包含了gossip版本的状态消息。 集群状态一发生变化(意味着不再收敛),集群就再次回到有倾向性的gossip。
gossip状态(gossip state or gossip status?有啥区别)接受者可以使用gossip版本(vector clock)来确定:
- 它拥有一个较新版本的gossip状态,此时它会将这个状态发回去
- 它拥有的是一个过时的状态,此时它会发回它自己的gossip状态并请求当前状态
- 它拥有的是一个冲突的状态,此时不同的版本会被合并后再发回
如果接收者和gossip的版本相同,gossip状态就不再发送或请求
gossip周期性的特性对于状态改变有非常好的批处理效果。例如,短时间内加入集群内同一个节点的一批节点,只会引起一次状态变化。
gossip消息会使用protobuf序列化同时再进行gzip压缩来降低负载。
####Membership Lifecycle
一个节点开始于joining状态。一旦所有的节点看到有新节点加入(通过gossip收敛)leader会将成员状态设置为up。
如果一个节点按照一种安全的符合预期的方式离开集群,则该节点状态变为leaving。当leader看到节点处于leaving状态的收敛,便会将节点变为exiting状态。
当所有的节点看到这个exiting状态(收敛)leader便将这个节点移出集群,并标记它为removed。
如果一个节点处于unreachable状态那么gossip收敛无法达成,因此任何leader的行为都无法进行(例如允许一个节点成为集群的一部分)。
leader想要进行任何进一步的操作,unreachable的节点状态必须改变。
它必须重新变为reachable或被标记为down。如果这个节点要重新加入集群,那么actor system必须重启,并且重新进行一次加入集群的过程。
经历了配置过的unreachable次数,集群可以通过leader来把一个节点自动置为down。
Note
如果你配置允许auto-down并且failure detector触发,而又没有配置合适的指标来将
unreachable的节点关闭,你将会得到一堆只有单节点的集群。 这是因为unreachable节点同样会将其他节点视为unreachable,然后成为自己那个集群(只有自己一个节点)的leader。
#####STATE DIAGRAM FOR THE MEMBER STATES
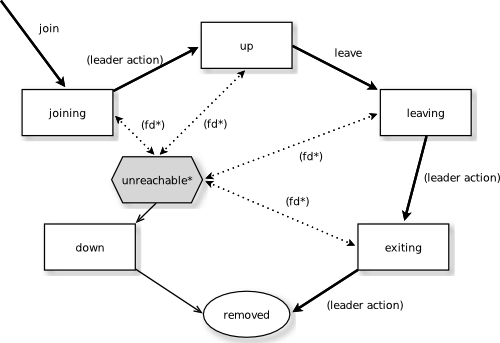
#####MEMBER STATES ######joining
加入集群的瞬间状态
######up
正常服务状态
######leaving / exiting
正常移出中状态
######down
被标记为停机(不再是集群决策的一部分)
######removed
“墓碑”状态(不再是集群成员)
#####USER ACTIONS ######join
让一个节点加入集群 - 可以是显示操作也可以是系统启动时将配置文件中指定的节点自动加入
######leave
让一个节点正常的离开集群
######down
将一个节点标记为停机
#####LEADER ACTIONS
leader有以下职责:
- 将一个节点挪入或挪出集群
- joining -> up
- exiting -> removed
#####FAILURE DETECTION AND UNREACHABILITY
-
fd*
监控节点的failure detector触发似的被监控节点被标记为
unreachable -
unreachable*
unreachable不是一个真正的成员状态,它更像是一个额外的标志位,表示集群无法与某个节点通信,在节点处于unreachable后failure detector可能发现节点又可以通信了,便会将这个标志位去掉。